我們都知道,
C語言是以陣列第一個元素的位址當成是陣列的位址(也就是說-->陣列名稱本身就是存放陣列位址的變數),
在c裡,陣列傳遞是採用傳址呼叫(call by address or call by pointer),
因為在呼叫函數傳遞參數時,無法將整個陣列傳遞(因為陣列可能很大),因此傳的是陣列開頭的位址,
okay,複習一下參數傳遞的觀念,
分為傳值(call by value)、傳址(call by address)、傳參考(call by reference)3種,
1.傳值call by value
當函數被呼叫時,將主程式的變數"複製"一份給副函數,主程式的變數跟副程式複製來的變數互相獨立,並且有各自獨立的記憶體空間,
假設main()呼叫函式funcB(p, q),則funcB中的p和q是把main()傳入的參數「複製」一份,
funcB()對p, q所做的任何運算都不會影響到main()中的p和q,因為funcB()執行完後,不會把複製的p, q丟回給main()。
寫成code:
void swap( int i, int j );
int main()
{
int i=5, j=10;
printf("before swap:i=%d(add=%p) j=%d(add=%p)\n",i,&i,j,&j);
printf("swap()work\n");
swap(i,j);
printf("i j in main():i=%d(add=%p) j=%d(add=%p)\n",i,&i,j,&j);
return 0;
}
void swap( int i, int j )
{
int temp;
temp = i;
i = j;
j = temp;
printf("i j in swap():i=%d(add=%p) j=%d(add=%p)\n",i,&i,j,&j);
}
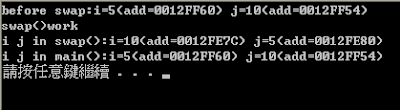
可以看到output中,main()和swap()裡的i和j是獨立的(記憶體位址也不同),
而經過swap進行變數互換後,也沒影響到main()裡原本的變數值,
當換成傳遞陣列時,可以看到結果不一樣了,
void timesTwo( int arr[] );
int main()
{
int arr[3]={1,3,5};
for(int i=0; i<3; i++)
printf("before swap:arr[%d]=%d(add=%p)\n",i,arr[i],&arr[i]);
printf("arr[] add=%p\n",arr);
printf("swap()work\n");
timesTwo(arr);
for(int i=0; i<3; i++)
{
arr[i] = arr[i]*2;
printf("arr[] in main():arr[%d]=%d(add=%p)\n",i,arr[i],&arr[i]);
}
printf("arr[] add =%p\n",arr);
return 0;
}
void timesTwo( int arr[] )
{
for(int i=0; i<3; i++)
{
arr[i] = arr[i]*2;
printf("arr[] in swap():arr[%d]=%d(add=%p)\n",i,arr[i],&arr[i]);
}
printf("arr[] add =%p\n",arr);
}
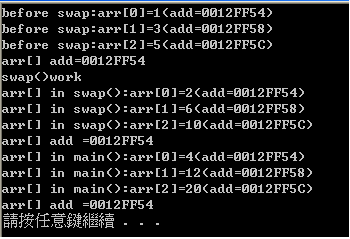
證實了開頭所說,C是以陣列第一個元素的位址當陣列的位址,且採用傳址(call by address)方式,
呼叫副函式timesTwo()後,函數所做的改變,直接改變main()裡array的值,這就是傳址(call by address),
傳址同樣可以用在一般變數,只要加上pointer即可,這方法可以讓函數直接改變原本變數值,也省去複製的步驟和記憶體空間,
void swap( int *i, int *j );
int main()
{
int i = 5, j = 10;
int *pt1 = &i;
int *pt2 = &j;
printf("before swap:\ni=%d(add=%p)\tj=%d(add=%p)\npt1=%d(add=%p)\tpt2=%d(add=%p)\n\n",i,&i,j,&j,*pt1,pt1,*pt2,pt2);
printf("swap()work\n");
swap(pt1, pt2);
printf("i j pt in main():\ni=%d(add=%p)\tj=%d(add=%p)\npt1=%d(add=%p)\tpt2=%d(add=%p)\n\n",i,&i,j,&j,*pt1,pt1,*pt2,pt2);
return 0;
}
void swap( int *i, int *j )
{
int temp;
temp = *i;
*i = *j;
*j = temp;
printf("i j pt in swap():\ni=%d(add=%p)\tj=%d(add=%p)\n\n",*i,i,*j,j);
}
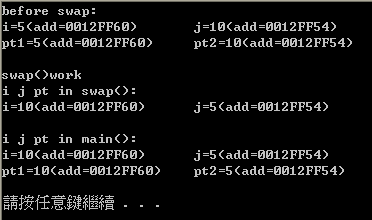
swap()呼叫前後,main()的i j跟swap裡i j用的都是同一塊記憶體,經過swap後,也因此i j直接互換的結果直接改變在main()裡,
這也是為什麼call by address又叫call by pointer,然後本質上他也是call by value的關係了!
當寫到2維陣列(或多維陣列)時,赫然發現事情已經不是如上所想的簡單了,
首先,這樣的陣列傳遞已經無法通過compile了,因為Compiler不知如何翻譯...待會會解釋why,
void timesTwo( int arr[][] );
int main()
{
int arr2[2][4]={ 1,3,5,7,2,4,6,8 };
...
}
如果這樣寫就可以通過compile,但把維度寫死一點都不彈性,未來要傳不同維度array給函數,不就哭了,
void timesTwo( int arr[2][4] ) {};
所以要換成這樣的寫法較佳,
void timesTwo( int arr[][4] ) {};
或這樣,
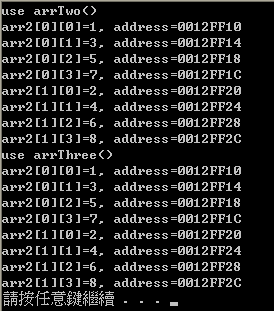
void timesThree( int (*arr)[4] ) {};
結果都是一樣,並且成功傳給function顯示,
2維陣列的行和列,其實是我們為了清楚理解陣列元素排列而想像出來的,實際上在記憶體配置並非如此,而是以線性模式配置,
不管幾維陣列,都是分配成一塊連續的記憶體空間去處理陣列,
如int arr2[2][4]陣列會分配成2*4*sizeof(int)大小記憶體區塊(如圖),依此類推,

如果要走訪2維陣列的話,要把它對應成一維來處理,
假設陣列int arr2[2][4]={ {1,3,5,7},{2,4,6,8} },
我們要存取arr2[p][q]的值,從記憶體觀點,我們要從arr2[p]的開頭後走q個單位到達arr2[p][q].
所以可以如此表示:arr2[p][q]=p*4+q

code可以這樣寫
void arrFour(int *arr, int rol, int col)
{
for(int i=0 ; i<rol ; i++) {
for(int j=0 ; j<col ; j++) {
arr[i*col+j] = arr[i*col+j]*2;
printf("array[%d][%d] in arrFour()= %d, address=%p\n", i, j, arr[i*col+j], &arr[i*col+j]);
}
}
printf( "address of array arr2 in arrFour()=%p\n", arr );
}
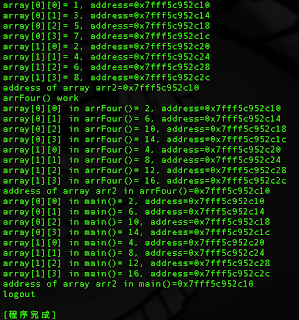
成功更改array每一個元素,可以看到arrFour執行前後,main()和function裡所使用的記憶體位置都是同一塊,改變也直接作用在原本array的value上,
這樣的寫法也增加了使用上的彈性,不用在宣告函數時寫死,
這也解答了為何 void timesTwo( int arr[][] ) 這樣寫無法compile了,因為compile無從計算起位置.












